Les moteurs de recherche, notamment Google, mais aussi ceux utilisés sur Amazon, Netflix ou YouTube, et ceux qu’utilisent votre ordinateur ou votre programme de messagerie, fonctionnent selon les mêmes principes :
- Le contenu faisant l’objet de votre recherche est d’abord indexé
- Un internaute saisit une requête avec ses mots
- Le moteur de recherche puise dans l’index les résultats qui correspondent le mieux à cette requête
- Les résultats sont classés, les plus pertinents figurant en tête de liste
Téléchargez notre Ebook gratuit « Introduction au SEO pour WordPress »
Si vous éditez un site sous WordPress, dans n’importe quel pays ou presque, ce qui vous intéresse principalement dans les moteurs de recherche (et motive la lecture de cet article), c’est votre classement dans Google. Gardez cependant toujours à l’esprit que d’autres moteurs de recherche existent et que Google n’est peut-être pas toujours le plus populaire d’entre eux.
En apprenant à connaître le fonctionnement des moteurs de recherche, vous pouvez optimiser votre site pour qu’il soit mieux classé et génère plus de trafic !
Une opportunité marketing unique
Être visible dans un moteur de recherche, cela peut générer du trafic, mais c’est aussi une opportunité marketing unique : vous êtes visible au moment précis où un internaute s’intéresse à vous, à votre produit ou à votre contenu. Imaginons par exemple que vous possédiez un restaurant indien à Seattle. Si vous êtes visible dans Google quand quelqu’un, à Seattle, tape la requête « restaurant indien », vous avez là un moyen extraordinairement efficace de toucher un nouveau client. Avec la plupart des autres outils marketing (par exemple, la distribution de flyers dans la rue), votre message est diffusé de force à des personnes qui n’ont pas demandé à recevoir cette information, ce qui réduit nettement vos chances de les convertir en clients. Vous risquez même éventuellement d’en agacer certaines et de perdre des clients potentiels !
Google ne fait pas de recherches sur le web
Dès les premières solutions de recherche de fichiers sur ordinateur, il est devenu évident qu’ouvrir et lire chacun des fichiers l’un après l’autre n’était pas un moyen efficace de trouver des résultats pertinents. Avec l’augmentation de la capacité de stockage des ordinateurs, passer le disque au peigne fin prenait trop de temps et accroissait en outre le risque d’endommager des lecteurs de disques fragiles.
Le saviez-vous ? Les premiers ordinateurs ne permettant pas les recherches sur fichiers, il était recommandé de classer ces derniers dans des répertoires et sous-répertoires. Appliquée au web, cette méthode a entraîné la création d’annuaires internet comme Yahoo ou DMOZ, afin de classer les sites web du monde entier dans une structure de type répertoire. Dans les années 90, ces sites jouissaient d’une popularité bien plus grande que celle des moteurs de recherche. DMOZ a même été intégré à Google de 2000 à 2011.
Le logiciel du moteur de recherche se sert de données stockées dans des index pour l’aider à obtenir plus efficacement des résultats. Un index est une partie de base de données qui stocke des informations dans un format accélérant les recherches. Par exemple, au lieu de rechercher un mot dans de multiples fichiers, l’index organise les données par mots : en listant tous les fichiers contenant un mot spécifique dans un index.
Google a créé son index et l’actualise en explorant le web. Lorsqu’il découvre une nouvelle page, il indexe le contenu de cette dernière. Il y retourne ensuite régulièrement pour vérifier si cette page a subi des modifications – et, si tel est le cas, il la réindexe. Lorsque vous lancez une recherche dans Google, la recherche est conduite sur l’index de Google, et non dans le web lui-même. Il est ainsi possible que Google propose un lien vers du contenu qui n’est plus en ligne, ou omette du contenu en ligne qui n’est pas encore indexé.
Le temps d’un bref instant, imaginez l’ampleur de l’index Google et l’ampleur du travail nécessaire pour le garder à jour. Google affirme explorer et indexer des centaines de milliards de pages web (et comme le note Kinsta, WordPress est utilisé par 43 % de tous les sites web d’Internet, ce qui, quand on y pense, est plutôt sympa). L’index dépasse largement 100 000 000 de gigaoctects en taille et nécessite de vastes bâtiments industriels pour héberger le matériel qui stocke les données. Les robots d’exploration, qui sont des programmes informatiques, revisitent et réindexent régulièrement des millions de pages web tous les jours.

Les requêtes formulées par des mots clés
Les recherches sont exécutées à l’aide de requêtes formulées par des mots. Vous pouvez taper ces mots dans la barre de recherche de Google ou, à la place, utiliser un logiciel de reconnaissance vocale.
Des personnes différentes utiliseront des méthodes différentes pour mener leurs recherches sur Google. Par exemple, une personne à Seattle cherchant un restaurant pourra simplement taper « restaurant » dans Google (en sachant que Google lui fournira uniquement des résultats pertinents locaux), d’autres taperont « restaurant Seattle », ou encore « restaurants à Seattle », etc. Quelqu’un, quelque part, tapera (ou dira) peut-être même quelque chose comme « pourriez-vous s’il vous plaît me conseiller un bon restaurant indien au centre-ville de Seattle, svp, merci beaucoup », et toutes ces requêtes obtiendront vite des résultats pertinents (ce qui prouve que la politesse est payante !).
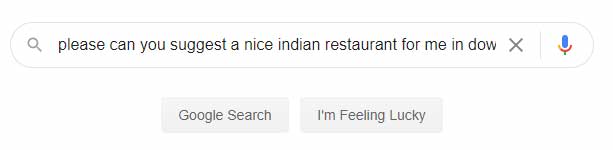
Google est prompt à fournir des résultats. On peut donc en déduire qu’il n’explore pas toutes les pages trouvées sur le web pour trouver celles correspondant aux mots clés tapés. Il est possible qu’il dispose d’index pour les recherches populaires (cela signifie qu’il tient à jour une liste d’URL correspondant à des requêtes précises composées de plusieurs mots). C’est assurément le cas de « Restaurants à Seattle ». Lorsqu’un internaute tape cette requête, Google dispose déjà d’une liste de pages pertinentes répondant à cette question.
Cela étant, la requête « pourriez-vous s’il vous plaît me conseiller un bon restaurant indien au centre-ville de Seattle, svp, merci beaucoup » n’a probablement jamais été formulée auparavant et il est peu probable que Google dispose d’une liste toute prête de pages pertinentes répondant à cette requête. Cela n’est pas un cas rare. Google indique que, tous les jours, 15 % des requêtes n’ont jamais fait l’objet de recherches antérieures.
Dans ces cas-là, Google décortique la requête pour en extraire les mots et expressions les plus pertinents qui correspondront le mieux possible à ses différents index. Au fil des ans, Google a progressé dans l’interprétation de ces requêtes plus complexes et y parvient actuellement mieux que les autres moteurs de recherche dans la plupart des langues.
Les algorithmes de classement des résultats
Il est admis que, pour toute requête, Google crée tout d’abord une liste de seulement 1 000 pages, qu’il classe ensuite de 1 à 1 000, éliminant certains résultats en cours de route. Il existe un algorithme pour trouver les 1 000 meilleures pages, et il en existe un autre pour classer ces 1 000 résultats de 1 à 1 000.
Le spécialiste du SEO Jason Barnard a développé une théorie selon laquelle Google possède de nombreux algorithmes qui calculent différents classements pour chaque page, sur la base de différents facteurs (pertinence, qualité, vitesse de page, etc.). Ceux-ci sont ensuite multipliés entre eux pour calculer une enchère. La page possédant l’enchère la plus haute possède le plus haut classement. Il souligne également que les scores étant le produit d’une multiplication, tout score très bas attribué à l’un des facteurs peut considérablement réduire l’enchère et le classement de la page.
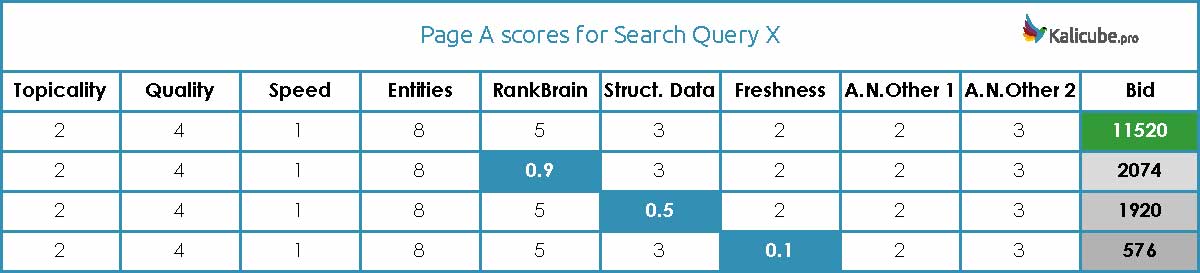
Cela ne reste pourtant que l’hypothèse d’un référenceur averti. Les détails du fonctionnement précis de Google constituent un secret bien gardé et Google nous rappelle que l’algorithme fait tous les jours l’objet de modifications et d’améliorations.
Les principaux facteurs, toutefois, sont assurément l’utilisation de mots dans les pages individuelles de votre site et les liens que ces pages reçoivent d’autres pages web (qu’il s’agisse de liens émanant de votre propre site ou de sites extérieurs). Moins importants, mais dotés d’un fort impact potentiel pour certains mots clés, sont les facteurs liés à l’expérience utilisateur, la vitesse de page, les réseaux sociaux et la réputation en ligne.
Après avoir classé les pages, Google décidera peut-être aussi d’écarter certains résultats. Cela peut simplement être le cas pour réduire le nombre de résultats provenant d’un même site, mais aussi pour filtrer les sites de spam ou des pages ayant du contenu adulte.
Généralement, vous obtenez les résultats de Google moins d’une seconde après l’envoi de votre requête.
Gardez également à l’esprit que les résultats de recherche sont personnalisés en fonction de votre localisation géographique et de votre historique de recherches. Ces facteurs peuvent faire de grosses différences selon l’ordinateur sur lequel est conduite la recherche.
Les SERP et les extraits
Pour chaque requête, Google affiche les résultats dans une SERP (Search Engine Results Page – page de résultats du moteur de recherche). Il est très rare que Google ne trouve aucun résultat en réponse à une requête.
En plus des résultats de la recherche sur le web, Google ajoute parfois des publicités Google Ads et les résultats d’autres moteurs de recherche Google tels que Google News, Google My Business, Google Images, etc.
Les résultats de toute recherche sur le web sont généralement de l’ordre de 10 par page. Chaque résultat possède un lien vers une page web, ainsi qu’une brève description. Ce résultat s’appelle un extrait. L’extrait peut également s’enrichir du logo du site, de commentaires, d’images, de prix et d’autres informations utiles.

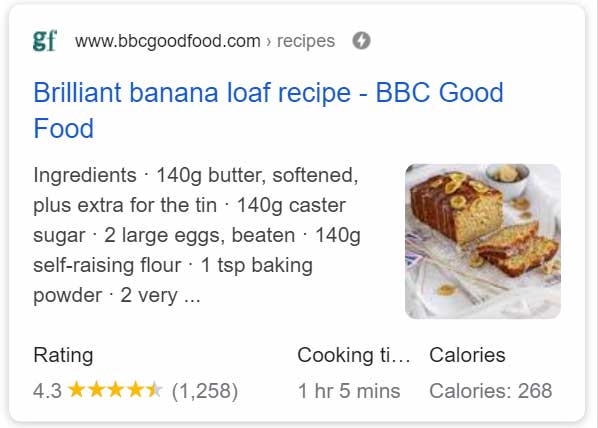
Les informations de l’extrait peuvent être fournies par le site web lui-même, à l’aide de balises spécifiques KEYWORD, META DESCRIPTION ou de données structurées Schema.org. La qualité de ces informations peut influencer Google dans le classement de votre page, mais elle est également importante pour inciter les internautes qui consultent les résultats à cliquer sur votre extrait et générer du trafic. Même si vous ne figurez qu’en troisième position, vous pouvez posséder un extrait visuellement attirant, qui incitera la plupart des internautes à cliquer sur votre lien plutôt que sur les deux premiers résultats.
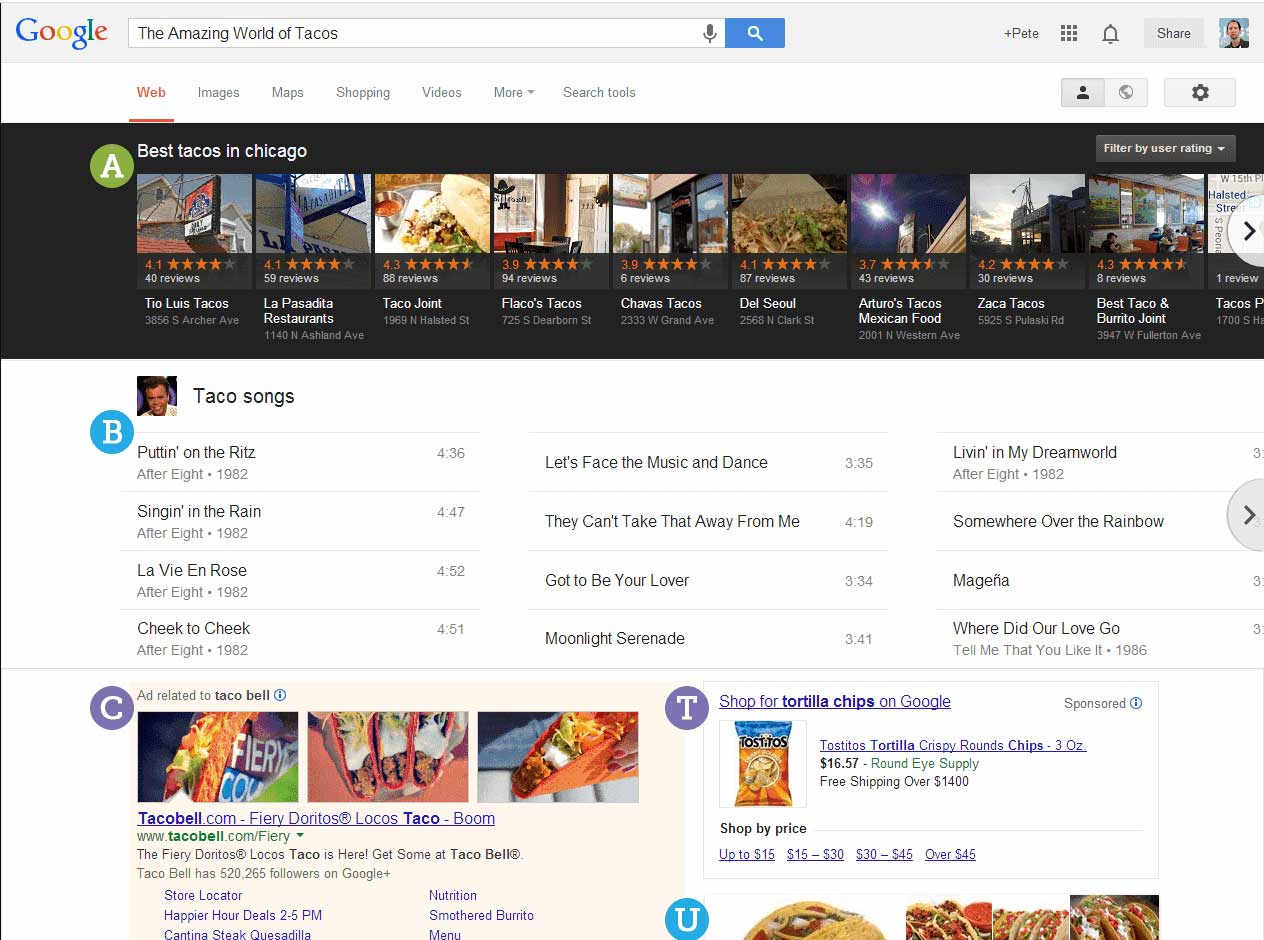
En 2013, Dr Peter J. Meyers fit un mash-up à partir de 24 types de résultats différents. Bien qu’il date un peu maintenant, il offre toujours une bonne introduction à la diversité des résultats possibles dans Google.
Qu’est-ce que le SEO ?
SEO est le sigle de Search Engine Optimization. Il désigne le travail effectué pour optimiser votre site web à destination des moteurs de recherche – et vous permettre d’être listé (gratuitement) dans Google lorsqu’une recherche pertinente pour votre site a lieu.
En comprenant comment fonctionnent les moteurs de recherche, on peut voir que les principales tâches, en SEO, consistent à :
- S’assurer que Google peut indexer correctement votre site, trouver tout votre contenu et tous vos liens entre les pages. Fournir un sitemap peut s’avérer utile pour y arriver.
- Comprendre les requêtes utilisées par votre public cible dans les moteurs de recherche et s’assurer que vos pages ou articles utilisent les mots clés de ces recherches et répondent à la question posée par l’utilisateur du moteur de recherche. La plupart des extensions SEO fournissent des outils qui permettent d’analyser les pages pour un mot clé donné.
- S’assurer que les balises qui comptent pour le SEO sont correctement remplies. En particulier, les balises TITLE et META DESCRIPTION. Vous aurez besoin d’une extension SEO pour y parvenir.
- Le cas échéant, fournir des données structurées Schema.org pour décrire votre site ou le contenu de vos pages en vue de produire des extraits enrichis. Là aussi, en utilisant une extension SEO vous permettant d’ajouter le Schema adapté à vos articles et pages pour obtenir des extraits enrichis.
- Développer et suivre des liens externes depuis d’autres sites web.
- Analyser votre classement dans les moteurs de recherche et le trafic qu’ils génèrent pour votre site
SEO peut également désigner le Search Engine Optimizer, c’est-à-dire la personne exécutant le travail décrit ci-dessus. Si cette personne n’est autre que vous, continuez à lire nos articles pour en savoir plus sur le gain de visibilité et de trafic pour votre site WordPress !
